In the quest to discern the true impact of an intervention, we must first establish a level playing field. The concept of baseline equivalence serves this purpose, ensuring that the groups under comparison are similar enough in key observed characteristics before the intervention takes place. Any discrepancies at baseline could muddy the waters, making it difficult to isolate the intervention’s effect from pre-existing differences.
Baseline equivalence is particularly crucial in scenarios where sample sizes are small or when we’re dealing with observational studies. Let’s say a company wants to evaluate a new algorithm designed to boost user engagement. If the group exposed to this new algorithm (the treatment group) already exhibited higher engagement levels than the control group prior to the experiment, any observed increase could simply be a continuation of their existing behavior, not necessarily a testament to the algorithm’s effectiveness.
3.1 Gauging Baseline Equivalence
To ascertain baseline equivalence, we turn to pre-intervention outcomes and other relevant observables. A common approach is to calculate the effect size, a standardized measure of the magnitude of an effect.
For continuous variables, Hedges’ g statistic is a popular choice (Hedges (1981)):
\[
g = \frac{\omega(y_t-y_c)}{\sqrt{\frac{(n_t - 1) s_t^2 + (n_c - 1) s_c^2}{n_t+n_c - 2}}}
\] where
\(y_t\) is the mean for the treatment group
\(y_c\) is the mean for the comparison group
\(n_t\) is the sample size for the treatment group
\(n_c\) is the sample size for the comparison group
\(s_t\) is the standard deviation for the treatment group
\(s_c\) is the standard deviation for the comparison group
\(\omega := 1 - \frac{3}{4(n_t+n_c)-9}\) is the small sample size correction.
For binary outcomes, Cox’s index comes into play (see Cox (1972)):
\(p_t\) is the the mean of the outcome in the intervention group
\(p_c\) is the mean of the outcome in the comparison group
\(\omega := 1 - \frac{3}{4(n_t+n_c)-9}\) is the small sample size correction.
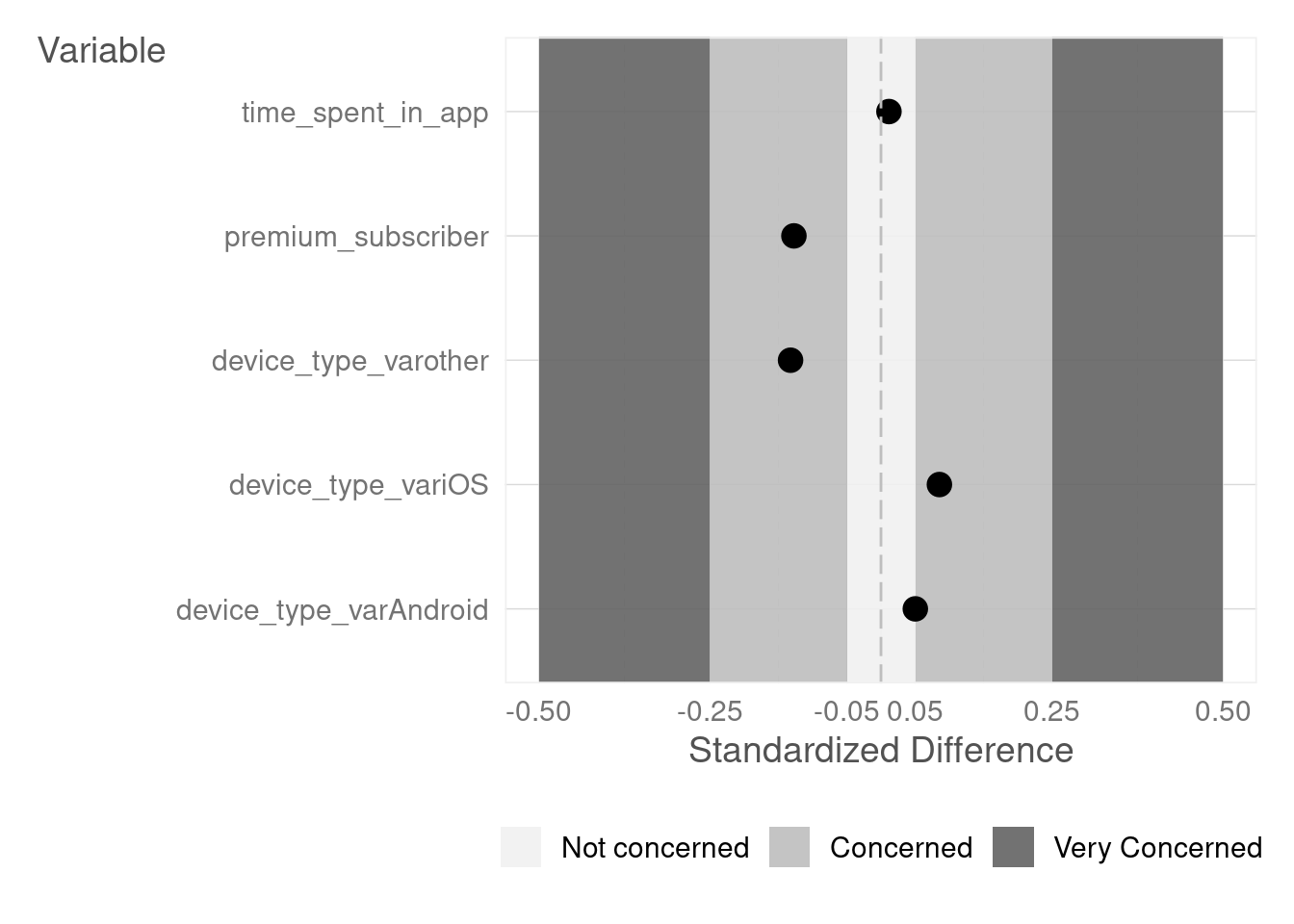
The general rule of thumb is that an absolute effect size greater than 0.25 signals a lack of baseline equivalence, and statistical adjustments are unlikely to fully remedy the situation. If the absolute effect size lies between 0.05 and 0.25, statistical adjustments become necessary. An absolute effect size below 0.05 indicates strong evidence of baseline equivalence.
3.2 Linking Baseline Equivalence to Potential Outcomes
The concept of baseline equivalence is intimately connected to the potential outcomes framework we discussed in Section 2.1. Baseline equivalence supports the crucial ignorability assumption in the potential outcomes framework, which states that treatment assignment is independent of the potential outcomes given observed covariates. When groups are equivalent at baseline, it’s more plausible that any differences in outcomes are due to the treatment rather than unobserved confounders.
By striving for baseline equivalence, we’re essentially attempting to create conditions that allow us to more accurately estimate the causal effects defined in the potential outcomes framework. This connection underscores the importance of assessing and establishing baseline equivalence in any causal inference study, whether experimental or observational.
3.3 The {imt} Package in R
The R package {imt} package provides a convenient way to check baseline equivalence using the imt::checkBaseline function and visualize the results with imt::balancePlot.
Warning: The `size` argument of `element_line()` is deprecated as of ggplot2 3.4.0.
ℹ Please use the `linewidth` argument instead.
ℹ The deprecated feature was likely used in the imt package.
Please report the issue at <https://github.com/google/imt/issues>.
3.4 The Importance of Baseline Equivalence
Whether your study design is experimental or observational, the principle of baseline equivalence should always be top of mind. It’s a fundamental building block for drawing valid causal inferences.
Remember, we can only assess baseline equivalence for the characteristics we can measure. It’s crucial to consider the possibility of unobservable factors that might differ between groups at baseline and potentially bias our findings. By acknowledging and addressing these potential confounders, we strengthen the rigor and reliability of our causal analyses.
TipLearn more
WWC (2020) What Works Clearinghouse Baseline Equivalence Standard.
Anderson and Maxwell (2018) Baseline Equivalence: What it is and Why it is Needed.
Cox, David R. 1972. “Regression Models and Life-Tables.”Journal of the Royal Statistical Society: Series B (Methodological) 34 (2): 187–202. https://doi.org/https://doi.org/10.1111/j.2517-6161.1972.tb00899.x.
Hedges, Larry V. 1981. “Distribution Theory for Glass’s Estimator of Effect Size and Related Estimators.”Journal of Educational Statistics 6 (2): 107–28. https://doi.org/10.3102/10769986006002107.
---title: "Baseline Equivalence"share: permalink: "https://book.martinez.fyi/baseline.html" description: "Business Data Science: What Does it Mean to Be Data-Driven?" linkedin: true email: true mastodon: true---<img src="img/baseline.jpg" align="right" height="280" alt="Baseline Equivalence"/>In the quest to discern the true impact of an intervention, we must firstestablish a level playing field. The concept of **baseline equivalence** servesthis purpose, ensuring that the groups under comparison are similar enough inkey observed characteristics before the intervention takes place. Anydiscrepancies at baseline could muddy the waters, making it difficult to isolatethe intervention's effect from pre-existing differences.Baseline equivalence is particularly crucial in scenarios where sample sizes aresmall or when we're dealing with observational studies. Let's say a companywants to evaluate a new algorithm designed to boost user engagement. If thegroup exposed to this new algorithm (the treatment group) already exhibitedhigher engagement levels than the control group prior to the experiment, anyobserved increase could simply be a continuation of their existing behavior, notnecessarily a testament to the algorithm's effectiveness.## Gauging Baseline Equivalence {#sec-baseline}To ascertain baseline equivalence, we turn to pre-intervention outcomes andother relevant observables. A common approach is to calculate the **effectsize**, a standardized measure of the magnitude of an effect.For **continuous variables**, Hedges' g statistic is a popular choice(@hedges1981distribution):$$g = \frac{\omega(y_t-y_c)}{\sqrt{\frac{(n_t - 1) s_t^2 + (n_c - 1) s_c^2}{n_t+n_c - 2}}}$$where - $y_t$ is the mean for the treatment group- $y_c$ is the mean for the comparison group- $n_t$ is the sample size for the treatment group- $n_c$ is the sample size for the comparison group- $s_t$ is the standard deviation for the treatment group- $s_c$ is the standard deviation for the comparison group- $\omega := 1 - \frac{3}{4(n_t+n_c)-9}$ is the small sample size correction.For **binary outcomes**, Cox's index comes into play (see @cox1972regression):$$d = \omega \left[ \ln\left(\frac{p_t}{1-p_t}\right) - \ln\left(\frac{p_c}{1-p_c}\right) \right]$$where:- $p_t$ is the the mean of the outcome in the intervention group- $p_c$ is the mean of the outcome in the comparison group- $\omega := 1 - \frac{3}{4(n_t+n_c)-9}$ is the small sample size correction.The general rule of thumb is that an absolute effect size greater than 0.25signals a lack of baseline equivalence, and statistical adjustments are unlikelyto fully remedy the situation. If the absolute effect size lies between 0.05and 0.25, statistical adjustments become necessary. An absolute effect sizebelow 0.05 indicates strong evidence of baseline equivalence.## Linking Baseline Equivalence to Potential OutcomesThe concept of baseline equivalence is intimately connected to the potentialoutcomes framework we discussed in @sec-potential. Baseline equivalence supportsthe crucial ignorability assumption in the potential outcomes framework, whichstates that treatment assignment is independent of the potential outcomes givenobserved covariates. When groups are equivalent at baseline, it's more plausiblethat any differences in outcomes are due to the treatment rather than unobservedconfounders.By striving for baseline equivalence, we're essentially attempting to createconditions that allow us to more accurately estimate the causal effects definedin the potential outcomes framework. This connection underscores the importanceof assessing and establishing baseline equivalence in any causal inferencestudy, whether experimental or observational.## The {imt} Package in R<img src="https://raw.githubusercontent.com/google/imt/refs/heads/main/man/figures/logo.png" align="right" height="138" alt="logo of the imt package"/>The R package [{imt}](https://github.com/google/imt) package provides a convenient way to check baselineequivalence using the `imt::checkBaseline` function and visualize the resultswith `imt::balancePlot`.```{r baseline}set.seed(123)data <-data.frame(time_spent_in_app =rnorm(1000, mean =60, sd =15),# Continuouspremium_subscriber =rbinom(1000, 1, 0.2),# Binarydevice_type =factor(sample(c("iOS", "Android", "other"), 1000, replace =TRUE )),# Factortreatment =factor(sample(c("control", "treatment" ), 1000, replace =TRUE)))# Check baseline equivalencebaseline_results <- imt::checkBaseline( data,variables =c("time_spent_in_app", "premium_subscriber", "device_type"),treatment ="treatment")imt::balancePlot(data = baseline_results)```## The Importance of Baseline EquivalenceWhether your study design is experimental or observational, the principle ofbaseline equivalence should always be top of mind. It's a fundamental buildingblock for drawing valid causal inferences.Remember, we can only assess baseline equivalence for the characteristics we canmeasure. It's crucial to consider the possibility of unobservable factors thatmight differ between groups at baseline and potentially bias our findings. Byacknowledging and addressing these potential confounders, we strengthen therigor and reliability of our causal analyses.::: {.callout-tip}## Learn more - @wwc_baseline What Works Clearinghouse Baseline Equivalence Standard. - @anderson2018baseline Baseline Equivalence: What it is and Why it is Needed.:::